Nejprve obecně k fulltextovému vyhledávání. Patrně nejznámější způsob, jak "fulltextově" vyhledávat, je použití operátoru LIKE %% v relační databázi. Tento přístup však není bezchybný - nedokáže nalézt všechny tvary slov a navíc ani není dostatečně rychlý.
Předpokládejme dva produkty - Jahody čerstvé a Čerstvá šťáva. Pokud bude uživatel vyhledávat výraz cerstvy, pomocí operátoru LIKE ani jeden z produktů nenalezneme. Slova se v názvech produktů od hledaného výrazu liší tím, že nejsou ve stejném tvaru, mají různou velikost písmen a obsahují diakritiku. Pokud by se podařilo jednotlivá slova názvu produktu převést do shodného tvaru a vyhledávání by probíhalo právě v nich, už by byla úspěšnost vyhledávání lepší. Lepší možností by bylo použití operátoru MATCH, ukážeme si ale, jak lze detailně nastavit fulltextové vyhledávání v Elasticsearch.
Procesu, kdy z textu vybíráme důležitá slova a ty ukládáme v základním tvaru, aby podle nich bylo možné vyhledávat, se nazývá indexace. Jde o činnost podobnou tvorbě rejstříku v knize. Soubor, ve kterém jsou uloženy termíny, v nichž se vyhledává, se nazývá invertovaný index. Úpravám textu na slova v základním tvaru se pak v kontextu Elasticsearch říká analýza.
Analýza textu
Při analýze textu probíhájí postupně úpravy, které se dají zařadit do následujících kategorií:
- filtrace znaků (character filters): odstranění nechtěných znaků ze vstupu (html značky nebo interpunkce)
- tokenizace (tokenizers): rozdělení vstupního textu na slova (tokeny), zpravidla mezerami
- filtrace tokenů (token filters): jde o úpravy nad jednotlivými slovy, může jít o převedení do prvního pádu, odstranění předpon/přípon, diakritiky nebo vypuštění nepodstatných slov
Nastavením všech těchto dílčích částí vzniká analyzér. Nastavení analyzérů se liší povahou dat a požadovaným způsobem vyhledáváním v nich. Různá bude také konfigurace pro různé jazyky, v tomto seriálu se však budeme zabývat pouze češtinou.
Nastavení analyzérů je součástí konfigurace indexu. Při jejich změně tak je třeba vytvořit nový index s novým nastavením a uložit do něj znovu data. Analyzérů může být v rámci indexu vytvořeno více, u každého pole dokumentu se pak při vytváření mapování definuje, jaký analyzér bude použit.
Nyní postupně vytvoříme analyzér pro indexaci českých textů. Analyzér budeme zkoumat skrz endpoint _analyze.
Výchozí analyzér
Elasticsearch po instalaci disponuje několika připravenými analyzéry. Pro pokročilé vyhledávání v češtině sice nebudou úplně dostačovat, v některých případech však mohou postačovat. Výchozím analyzérem v Elasticsearch je standard, který převede text na malá písmena, odstraní většinu interpunkce a rozdělí slova mezerami na jednotlivé termy.
Vytvoříme nový index products (bez žádného dalšího nastavení - analyzér standard je vždy dostupný) a necháme zanalyzovat název ukládaného produktu Jahody čerstvé - ve vaničce:
// smazání dříve vytvořeného indexu
DELETE products
// vytvožení nového prázdného indexu
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}
// Otestování analyzéru
GET products/_analyze
{
"analyzer": "standard",
"text": "Jahody čerstvé - ve vaničce"
}
Po spuštění těchto příkazů v Kibaně obdržíme následující výstup:
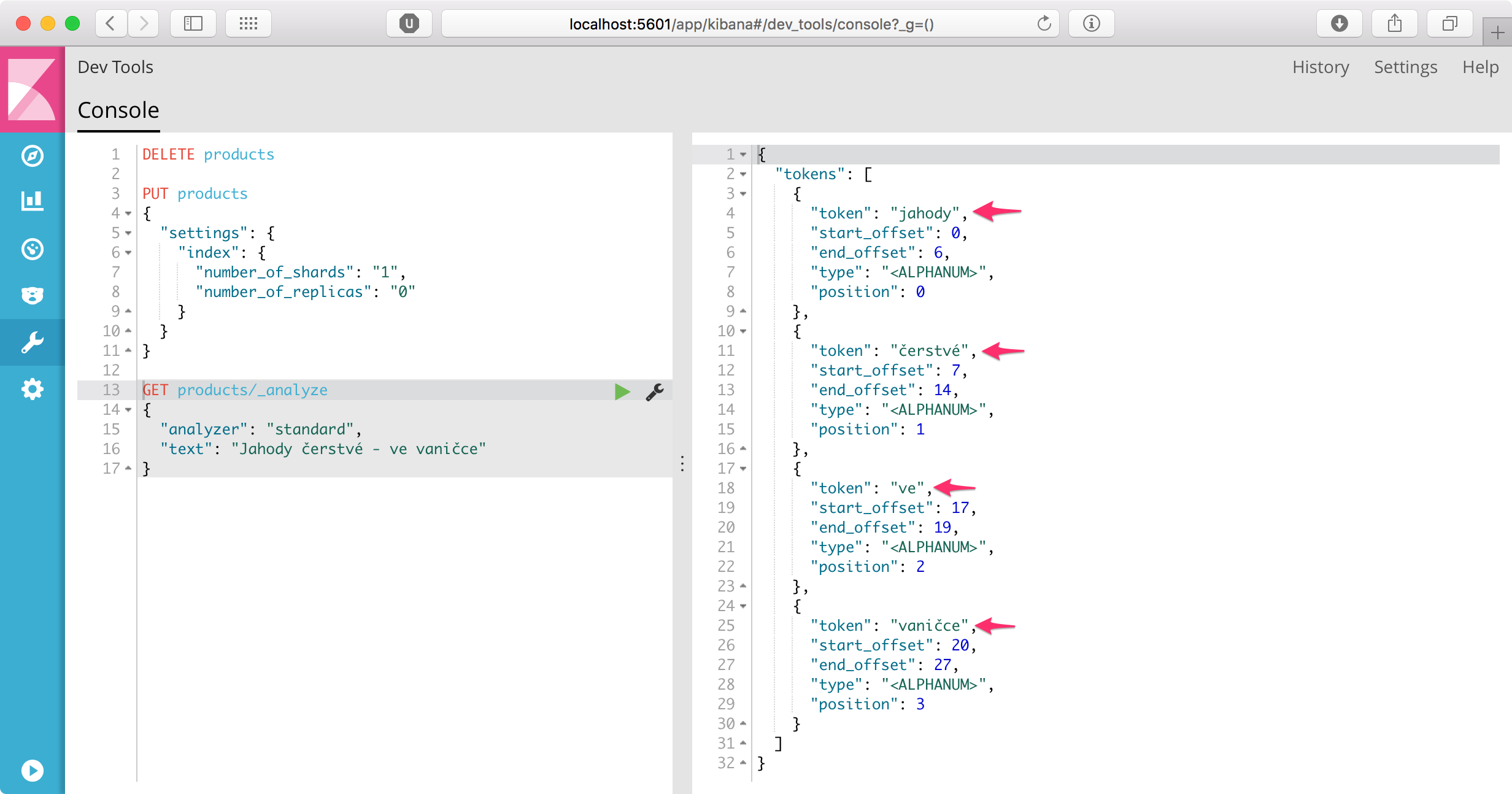
Výstupem jsou výrazy (termy) jahody, čerstvé, ve, vaničce. Slova byla rozdělěna mezerami, převedena na malá písmena, zmizela pomlčka. Kdybychom hledali výraz jahody, už bychom produkt nalezli, protože při jeho analýze stejným analyzérem bychom dostali slovo jahody, které je uvedeno v termínech hledaného produktu. Stále si však neumíme poradit s diakrtikou (vyhledat cerstve) ani s tvaroslovím (vyhledat čerstvá jahoda).
Částečně nám s tím může pomoci použití předdefinovaného českého analyzéru:
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "czech"
}
}
}
}
}
}
GET products/_analyze
{
"analyzer": "czech",
"text": "Jahody čerstvé - ve vaničce"
}
// "jahod", "čerstv", "vaničk"
Výstupem jsou slova převedená na malá písmena a ořezaná o koncovky. Díky tomu je možné vyhledat i slova v různých tvarech - při vyhledávání dojde také k oříznutí koncovek a porovnávají se pak tato analyzovaná slova.
Pro dosažení lepších výsledků však postupně vytvoříme vlastní analyzér, který by měl nakonec poskytovat lepší výsledky vyhledávání.
Převod na malá písmena
Nejprve tedy vytvoříme vlastní (custom) analyzér, který dělá totéž jako standard bez nastavení češtiny. Ten budeme dále rozšiřovat o další způsoby analýzy textu. Tento analyzér při indexaci rozdělí text na jednotlivá slova a ta převede na malá písmena:
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase"]
}
}
}
}
}
}
Z nastavení můžeme vyčíst, že:
- Vytváří se analyzér s názvem
czechv indexuproducts - Analyzér je tvořen jedním token filtrem
lowercase(další budeme přidávat) - Analyzér je dále tvořen tokenizérem
standard(tokenizér je vždy jen jeden) - Token filtr
lowercasepřevede každý vytvořený token na malá písmena
Tímto analyzérem můžeme zanalyzovat znovu titulek produktu
GET products/_analyze
{
"analyzer": "czech",
"text": "Jahody čerstvé - ve vaničce"
}
// jahody, čerstvé, vaničce
Výstup je shodný jako v případě použití standard analyzéru. Aby bylo vyhledávání v češtině použitelné, bude třeba analyzér rozšířit o další filtry.
Odstranění diakritiky
Dalším krokem je přidání filtru pro odstranění diakritiky. V Elasticsearch je pro tento účel dostupný filtr asciifolding. Ten převádí všechny ne-ascii znaky na jejich ascii variantu, tedy například Č ⇒ C, ř ⇒ r atd.
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "custom",
"tokenizer": "standard",
"filter": ["asciifolding", "lowercase"]
}
}
}
}
}
}
GET products/_analyze
{
"analyzer": "czech",
"text": "Jahody čerstvé - ve vaničce"
}
// jahody, cerstve, ve, vanicce
Do seznamu filtrů přibyl asciifolding, přičemž tokeny těmito filtry prochází postupně - nejprve je odstraněna diakritika, následně je převedeno na malá písmena. Výstup provedené analýzy je už o něco použitelnější než v předchozím případě: jahody, cerstve, ve, vanicce.
Token filtr asciifolding je však poměrně jednoduchý, pro plnou funkci češtiny je lepší použít filtr icu_folding. Ten není automaticky součástí Elasticsearch, nainstalovali jsme jej v první kapitole tohoto seriálu. Filtr icu_folding navíc oproti asciifolding počítá s významem jednotlivých znaků v rámci daného jazyka. Například ví, že písmena c a h za sebou tvoří písmeno ch. Díky tomu je možné například správně řadit podle české abecedy. Lépe si také poradí se speciálními znaky UTF-8, je však třeba počítat s tím, že je taková analýza dražší - je tedy nutné zvážit, zda pro daný účel nebude asciifolding dostačovat.
Tvarosloví
Nyní se dostáváme k tomu, co je u českého jazyka komplikovanější než například u angličtiny. Slova totiž mění svůj tvar - dochází k skloňování u jmen, časování u sloves a dalším změnám, obecně řečeno dochází k ohýbání slov. Abychom dokázali nalézt tatáž slova v různých tvarech, převedeme je do jejich základního tvaru, tedy například prvního pádu jednotného čísla v případě podstatných jmen. Způsobů, jak zjistit základní tvar je více, s Elasticsearch budeme používat dva - algoritmickou a slovníkovou stematizaci.
Algoritmická stematizace
Stemmer je algoritmus, který pro nalezení základního tvaru využívá sady pravidel daného jazyka (například seznamu koncevek), což má své výhody i nevýhody. Výhodou je, že takový stemmer nemusí znát všechna slova v daném jazyce, pouze pracuje s sadou pravidel, pomocí nichž velmi rychle převede slovo na základní tvar (nebo jen odstraní koncovky). Nevýhodou je pak určitá nepřesnost, kdy mohou být slova převáděna chybně, protoženení snadné obsáhnout všechna pravidla a výjimky daného jazyka.
V Elasticsearch je český stemmer standardně k dispozici, stačí jej jen přidat do nastavení analyzéru jako další filtr.
Do nastavení analyzéru tak přibyde sekce filter, která obsahuje nastavení dostupných filtrů. Zde je filtr stemmer nastaven na použití češtiny pomocí "name": "czech". Tato konfigurace je nazvána czech_stemmer a je použita v analyzátoru czech:
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"czech_stemmer",
"asciifolding",
"lowercase"
]
}
},
"filter": {
"czech_stemmer": {
"type": "stemmer",
"name": "czech"
}
}
}
}
}
}
GET products/_analyze
{
"analyzer": "czech",
"text": "Jahody čerstvé - ve vaničce"
}
// jahod, cerstv, ve, vanick
Výstupem provedené analýzy jsou termíny jahod, cerstv, ve, vanick. Zde je vidět, že Elasticsearch zahazuje nalezené přípony a vznikají tak neexistující slova. Pokud ale budeme vyhledávat slovo vanička, bude také převedno na vanick, je tedy toto chování v pořádku.
Stematizace pomocí slovníku
Přesnějšího převodu slov na základní tvar lze dostáhnout použitím slovníku obsahující veškerá slova pro daný jazyk. To není nic nereálného - textové editory takové slovníky obsahují a právě proto umí červeně podtrhávat chyby.
Elasticsearch disponuje filtrem hunspell, který umí využít volně dostupných slovníků Hunspell, které používá například kancelářský balík Open Office. Pokud je nemáte v Elasticsearch nainstalované, návod naleznete v druhém dílu tohoto seriálu. Slovníky jsou textové soubory obsahující slova daného jazyka včetně informací o tom, jak se skloňují nebo časují. Ty jsou uležené ve složce s konfigurací Elasticsearch, v nastavení filtru pak stačí jen definovat, jaký slovník se má použít. Pokud máme český slovník uložený ve složce config/cs_CZ, v nastavení filtru použijeme jako jazyk cs_CZ. Nahradíme tedy filtr stemmer za hunspell a můžeme porovnat výsledky analýzy:
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"czech_hunspell",
"asciifolding",
"lowercase"
]
}
},
"filter": {
"czech_hunspell": {
"type": "hunspell",
"locale": "cs_CZ"
}
}
}
}
}
}
GET products/_analyze
{
"analyzer": "czech",
"text": "Jahody čerstvé - ve vaničce"
}
// jahoda, jahoda, cerstvy, ve, vanicka
Výstupem provedené analýzy jsou termíny jahoda, jahoda, cerstvy, ve, vanicka. Ve výstupu se objevuje slovo jahoda dvakrát - filtr hunspell totiž vytvořil dvě slova s rozdílným počátečním písmenem (Jahoda a jahoda), která byla následně převedena na malá písmena. Řešením by bylo provést převod na malá písmena jako první v řadě filtrů.
Výstupem analýzy jsou tak existující slova v základním tvaru. Výhodou tohoto přístupu je větší přesnost oproti použití algoritmické stematizace. Nevýhodou je však to, že slovník nemůže pokrýt všechna existující slova v daném jazyce, ať už jde o různá nářečí, hantýrku nebo různé hovorové výrazy. Oproti algoritmické stematizaci je také tento filtr náročnější výkonově, musí totiž celý slovník načíst do paměti a v něm složitěji vyhledávat. Většinou si tedy vystačíme se stamatizací algoritmickou, pro dosažení lepších výsledků a cenu vyšší složitosti je však vhodné využít stematizaci pomocí slovníku.
Využití slovníku má také tu výhodu, že můžeme definovat vlastní sadu slov, která jsou například specifická pro danou oblast. Lze tak Elasticsearch "naučit" pracovat se slovy, která ve slovnících nejsou. Samostatnou kapitolou je pak práce se slovy, která mají stejný význam (synonyma). Pro tento účel lze využít filtr synonym, který může použít existující seznam synonym (je také součástí Hunspell slovníků) nebo lze definovat vlastní.
Odstranění nevýznamných slov
Poslední důležitou částí analyzéru je filtrace slov nepodstatných pro vyhledávání. V názvech produktů jich pravděpodobně mnoho nebude, nicméně při indexaci delších textů zjistíme, že řada slov se vyskytuje napříč dokumenty tak často, že podle nich prakticky nelze vyhledávat. Jde zpravidla o spojky nebo předložky. Elasticsearch si s tím částečně poradí sám - při vyhledávání také počítá s významností jednotlivých termínů vůči četnosti jejich výskytu v celém indexu, je však zbytečné jej vytěžovat indexací takových slov.
Taková slova se nazývají stop slova a Elasticsearch disponuje jejich sadou pro češtinu, k dispozici jsou jako _czech_ v rámci filtru stop. Filtraci stopslov je možné zobecnit a filtrovat slova dle jejich délky - k tomu je možné použít filtr length.
Při analýze také můžou vzniknout duplicitní slova, jako se stalo při slovníkové stematizaci slova s velkým počátečním písmenem. Zbavit se těchto duplicitních slov lze filtrem unique. Je však důležité povolit možnost only_on_same_position, která zabrání mazání duplicit napříč celým indexovaným textem. Tím bysme přišli o to, že vícekrát se vyskytující slovo je důležité pro indexovaný text. Nastavení těchto filtrů může vypadat následovně:
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"czech_stop",
"czech_length",
"czech_unique"
]
}
},
"filter": {
"czech_stop": {
"type": "stop",
"stopwords": ["že", "_czech_"]
},
"czech_length": {
"type": "length",
"min": 2
},
"czech_unique": {
"type": "unique",
"only_on_same_position": true
}
}
}
}
}
}
GET products/_analyze
{
"analyzer": "czech",
"text": "Jahody čerstvé - ve vaničce"
}
// Jahody, čerstvé, vaničce
Výstupem této analýzy jsou slova Jahody, čerstvé, vaničce.
Kompletní analyzér pro češtinu
Nyní známe všechna důležitá nastavení, abychom mohli vytvořit funkční analyzér pro češtinu. Je třeba říct, že neexistuje jediné správné a optimální nasavení analýzy, různá povaha dat a různé požadavky na vyhledávání budou vyžadovat různá nastavení analyzérů. I v rámci jednoho indexu tak lze vytvořit analyzérů více a použít zvlášť pro jednotlivá pole dokumentů. Je také nutné vzít v potaz množství dat a požadavky na výkonnost, kdy bude nutné nalézt rovnováhu mezi přesností a rychlostí indexace a vyhledávání.
V tuto chvíli tak definujeme analyzér, který může být výchozím bodem při implementaci a ladění českého vyhledávání.
DELETE products
PUT products
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"analysis": {
"analyzer": {
"czech": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"czech_stop",
"czech_hunspell",
"lowercase",
"czech_stop",
"icu_folding",
"unique_on_same_position"
]
}
},
"filter": {
"czech_hunspell": {
"type": "hunspell",
"locale": "cs_CZ"
},
"czech_stop": {
"type": "stop",
"stopwords": ["že", "_czech_"]
},
"unique_on_same_position": {
"type": "unique",
"only_on_same_position": true
}
}
}
}
}
}
V tomto analyzéru nejprve odstraníme stop slova, protože chceme minimalizovat množství slov, které se poměrně draze převádí pomocí slovníku na základní tvar. Stop slova včak nejsou k dispozici ve všech tvarech, je tedy nutné tento filtr následně opakovat. Dále jsou tokeny převedeny na malá písmena a odstraněna diakritika. Nakonec jsou odstraněny duplicity.
Nyní můžeme definovat mapování, které pro pole title využije nastavení tohoto analyzéru a uložit do indexu několik dokumentů:
PUT products/_mapping/products
{
"products": {
"properties": {
"title": {
"type": "text",
"analyzer": "czech"
}
}
}
}
PUT products/products/1
{
"title": "Jahody čerstvé - ve vaničce"
}
PUT products/products/2
{
"title": "Jahoda mražená"
}
PUT products/products/3
{
"title": "Maliny - vanička"
}
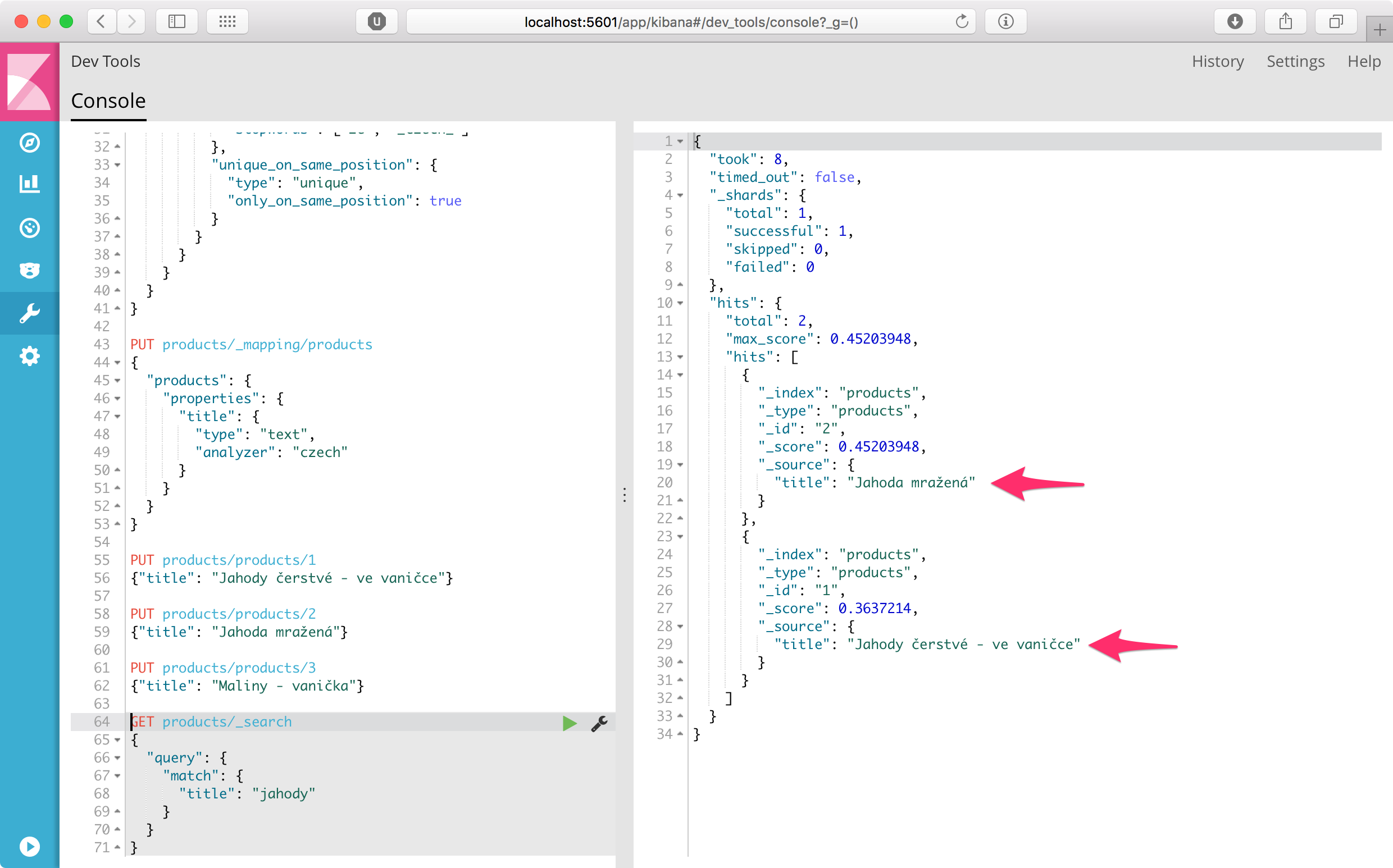
V těchto dokumentech můžeme konečně vyhledávat, nezávisle na pádu jmen, diakritice nebo velikosti písmen:
GET products/_search
{
"query": {
"match": {
"title": "jahody"
}
}
}
// "Jahoda mražená", "Jahody čerstvé - ve vaničce"
GET products/_search
{
"query": {
"match": {
"title": "Vanicka"
}
}
}
// "Maliny - vanička", "Jahody čerstvé - ve vaničce"
Výše uvedené vyhledávání pak v Kibaně vypadá následovně:
V tuto chvíli máme k dispozici základ pro vyhledávání v češtině. V následující kapitole se budeme věnovat pokročilejšímu vyhledávání v reálných datech, kdy budeme kombinovat vyhledávání v různých polích s různou váhou.