Než se pustíme do instalace a budování vyhledávání, považuji za důležité se seznámit se základními pojmy a principy, které nás budou celým seriálem provázet. Vysvětluji zde jak pojmy, které souvisí s fulltextovým vyhledáváním, tak také ty, které jsou důležité při práci s nástrojem Elasticsearch.
Indexy, dokumeny, pole, typy
Tak jako se v relační databázi setkáváme s tabulkami, sloupci a řádky, tak zde se setkáváme s pojmy obdobnými. Elasticsearch ale není relační databáze, jde o dokumentové úložiště, zařadit jej můžeme do NoSQL databází.
Dokument je textový soubor, který obsahuje informace, v nichž bude probíhat vyhledávání. V případě Elasticsearch jde konkrétně o soubor formátu JSON. Pokud bychom mluvili o produktu prodávaném v e-shopu, dokument uložený v Elasticsearch by mohl v nejjednodušší podobě vypadat následovně:
{
"id": 102146,
"title": "Apple iPhone 7 32GB bílý",
"brand": "Apple",
"price": 21190
}
Dokument je tvořen poli (fields) různých datových typů. V případě Elasticsearch není nutné je definovat předem, Elasticsearch je ve výchozím stavu vytvoří sám na základě struktury dokumentu. Proto je označován jako bezschémové úložiště. V rámci indexu však musí mít jedno pole vždy totožný datový typ. Není možné například uložit id jednou jako integer a podruhé jako string - na to je třeba pamatovat, pokud data kopírujete z jiné databáze typu MongoDB.
Dokumenty jsou ukládány do indexu, což je obdoba databázového schématu ve světě relačních databází. Na jeho úrovni je možné nastavovat parametry úložiště společné pro celou sadu dokumentů. V rámci indexu jsou pak definovány typy (type), což označuje skupinu dokumentů obdobného tvaru. Pokud bychom chtěli do Elasticsearche ukládat produkty a objednávky, bylo by možné je uložit do jednoho indexu a vytvořit dva typy - orders a products. V praxi je však výhodnější takto odlišné dokumenty uložit do různých indexů, protože většina konfigurace je dostupná právě na úrovni indexu. Pokud by měl produkt a objednávka pole se stejným názvem, ale různým datovým typem, nebylo by možné je ani do společného indexu uložit.
Můžeme zde nalézt analogii k přístupu relačních databází. Pro představu by se dal vztah mezi pojmy Elasticsearch a relační databáze vyjádřit následovně:
| Elasticsearch | Relační databáze |
| Index | Databáze |
| Typ (type) | Tabulka |
| Dokument (document) | Záznam (řádek tabulky) |
| Pole (field) | Atribut (sloupec tabulky) |
Cluster, repliky, shardy
Elasticsearch je od počátku navržen tak, aby běžel v cloudu. Při produkčním nasazení tak budete pravděpodobně chtít vytvořit cluster - nasadit jej na více serverů, což umožní distribuovat zátěž a zvýšit dostupnost služby.
K tomu, aby mohl být index dostupný na více serverech, jsou využívány shardy, což označuje fyzické rozdělení indexu na více částí. Při rozdělení indexu na shardy lze urychlit vyhledávání - dotazy jsou spouštěny na každém shardu zvlášť, dochází tak k jejich paralelizaci.
Aby bylo zajištěno, že nedojde ke ztrátě dat, jsou k shardům vytvářeny jejich repliky. Pokud tak dojde k výpadku serveru, pravděpodobně se nachází kopie ztracených dat na některém z dalších serverů (nodů), která je ihned využita a automaticky replikována na zdravé servery.
V rámci tohoto tutoriálu se nastavení shardů a replik budeme věnovat až v samém závěru, pro lokální vývoj je dostačující vytvoření jediného shardu bez replik. Takové nastavení pravděpodobně postačí i na první produkční spuštění, je však třeba počítat s tím, že data nejsou nikde replikována.
Fulltextové vyhledávání
Přestože to může znít triviálně, definujme ještě pojem fulltextové vyhledávání. Uživatel si nejprve musí představit, co chce vlastně vyhledávat a na základě této představy zformulovat dotaz, který zadá do vyhledávacího pole. Vyhledávač musí následně vyhodnotit, co chtěl uživatel vyhledat a vrátit mu co nejrelevantnější výsledky. A právě to je to obtížné na celém vyhledávání - výsledky jsou psané člověkem přirozeným jazykem se všemi chybami a nepřestnostmi, které jsou s tím spojeny. Naším cílem je však dodat takové výsledky, které jej uspokojí a dodají mu tak určitý zážitek z proběhlého vyhledávání. Lidsky řečeno - uživatel najde to, co hledá.
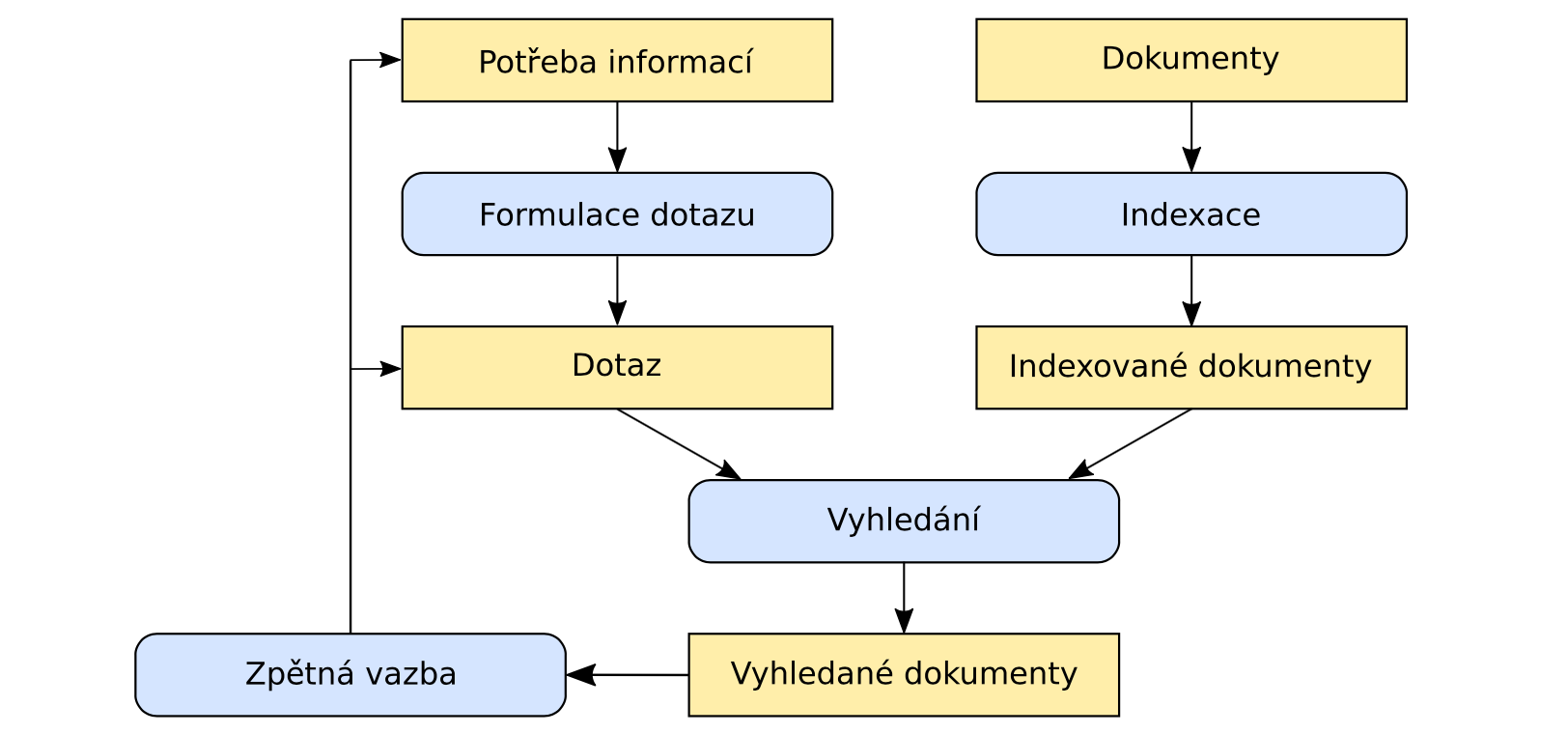
Indexace
Indexace je proces, při kterém jsou dokumenty ukládány do (invertovaného) indexu. Nejde o nějakou specialitu Elasticsearch, pojem jako takový je znám mnohem déle a označuje proces, při kterém jsou textové dokumenty ukládány do speciálního úložiště (indexu), ve tvaru optimalizovaném pro vyhledávání. Představte si to jako rejstřík knihy, ve kterém jsou uspořádány důležité termíny v základním tvaru, seřazeny podle abecedy. Bylo by totiž nemyslitelné pro nalezení hledaného termínu procházet celou knihu, stránku po stránce.
Při indexaci se tedy dokument transformuje do tvaru, který umožňuje vyhledávání. Takové transformace jsou například použití pouze relevantních slov (a vypuštění těch nedůležitých), jejich převedení na základní tvar (jednotné číslo, první pád...) a následné uložení do vhodného úložiště.
Tímto jsme se seznámili s základními pojmy a můžeme se pustit do instalace Elasticsearch a dalších potřebných nástrojů.