Dokud vám na serveru běží pár kontejnerů, dají se jejich logy procházet ručně pomocí příkazu docker logs. S rostoucím počtem kontejnerů je ale obtížnější v logách něco najít. V tu chvíli může situaci usnadnit agregace logů. Jakmile máte logy na jednom místě, můžete v nich vyhledávat a filtrovat, je práce s nimi snažší. Jedním z nástrojů, který toto umožňuje se jmenuje Elastic Stack, dříve známý jako ELK Stack.

Pro absolvování tohoto tutoriálu předpokládám nainstalovaný Docker a docker-compose. Pokud jej ještě nemáte, postupujte podle oficiálního návodu. Tento článek předpokládá, že Docker běží nativně a kontejnery jsou dostupné přes localhost. Protože je ale tato funkčnost zatím oficiálně jen na Linuxu (pro OS X je ve verzi beta), je možné, že máte docker ve virtuálním stroji vytvořeným pomocí docker-machine. V tom případě nahraďte localhost ip adresou, kterou získáte pomocí docker-machine ip.
Elastic Stack
Elastic Stack sám o sobě není jediná aplikace, jde o sadu tří nástrojů, konkrétně se jedná o Elasticsearch, Logstash a Kibana. Ty bývají často použity společně (a například u Kibany by to ani jinak nešlo, protože se umí připojit jen na Elasticsearch).

Elastic stack oproti ELK stacku nenabízí prakticky nic nového, jde především o sjednocení verzí, nemusíte si tedy hlídat, které verze Elasticsearche, Kibany a Logstashe jsou vzájemně kompatibilní. Více na webu elastic.co. Pojďme se nyní podívat na jednotlivé části stacku.
Logstash
Logstash je nástroj, který umí vzít nějaký vstup, transformovat jej a následně jej někam uložit. Do konfiguračního souboru můžete zapsat všemožné kombinace vstupů, výstupů a filtrů. Vstupem může být soubor, data v Redisu nebo nějakém message brokeru. Můžete je také pouze nechat naslouchat na určeném portu a data mu dodávat z vaší aplikace, nebo použít nějaký jiný nástroj. Výstupem může být například Elasticsearch, soubor, standardní výstup... Popis všech možností by byl hodně dlouhý, odkážu radši na oficiální dokumentaci, kde můžete najít jak možné vstupy tak výstupy. Filtrem se rozumí různé transformace a parsování vstupních dat, například rozpadnutí záznamu v Apache access logu, CSV, JSONu...

Elasticsearch
Elasticsearch je škálovatelné úložiště, do kterého můžete uložit lobovolný dokument ve formátu JSON. Je bezschémový, nemusíte tedy předem definovat sloupce jako v relační databázi. Je také škálovatelný, stačí spustit více instancí, data se automaticky rozloží mezi nody a dotaz můžete poslat na kterýkoliv z nich. Disponuje velmi dobrým fulltextovým vyhledáváním, pro které bývá často primárně použit, to však v tomto případě nevyužijeme.

Kibana
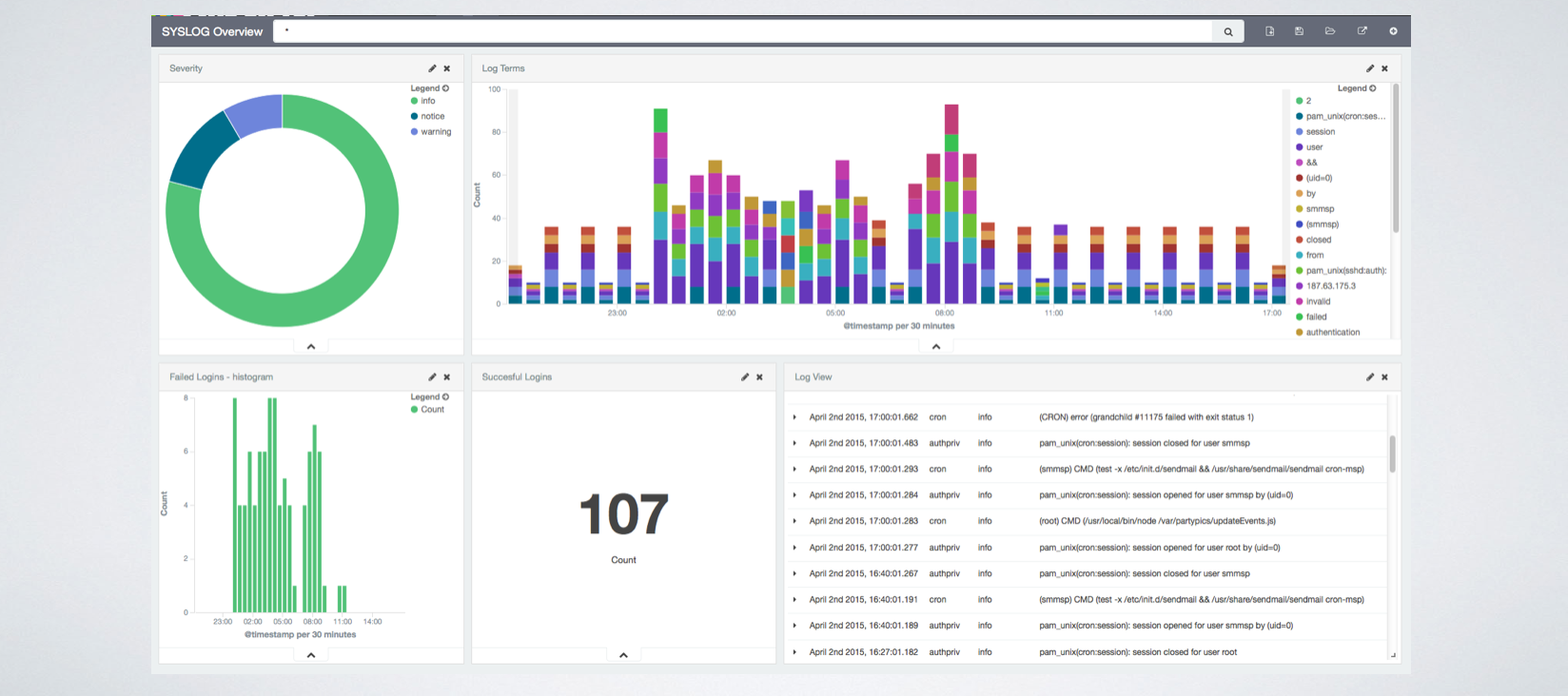
Kibana je poslední částí, se kterou budete nakonec pracovat nejčastěji. Je to webové rozhraní, které umí číst data z Elasticsearche a z nich vytvářet grafy, tabulky, metriky. Nad vytvořenými dashboardy můžete fulltextově vyhledávat, filtrovat data. Vytvořený dashboard v Kibaně může vypadat například takto:
Spuštění Elastic Stacku
Protože budeme agregovat logy Dockeru, předpokládám, že máte Docker nainstalovaný. Spustit samotný Elastic Stack je otázkou vytvoření souboru docker-compose.yml a následným spouštěním pomocí nástroje docker-compose.
V soboru docker-compose.yml definuji tři sekce, z káždé následně vznikne jeden kontejner. Pro každou sekci využiji oficiální Docker image. Důležité je zpřístupnění portu 5601, abychom mohli otevřít Kibanu v browseru. V commandu logstashe je definováno jak bude spuštěn. Parametr -e znamená, že bude následovat konfigurace (která je jinak v souboru). V ní je definován jako vstup podt 5000 a jako výstup Elasticsearch. Vstupní port 5000 je také zveřejněn.
kibana:
image: kibana
links:
- 'elastic:elasticsearch'
ports:
- '5601:5601'
logstash:
image: logstash
command: 'logstash -e "input { tcp { port => 5000 } } output { elasticsearch { hosts => elastic } }"'
ports:
- '5000/tcp:5000/tcp'
links:
- elastic
elastic:
image: elasticsearch
Uložte tento soubor a následně spusťte příkaz docker-compose up. Mělo by být vidět, jak jednotlivé služby startují:
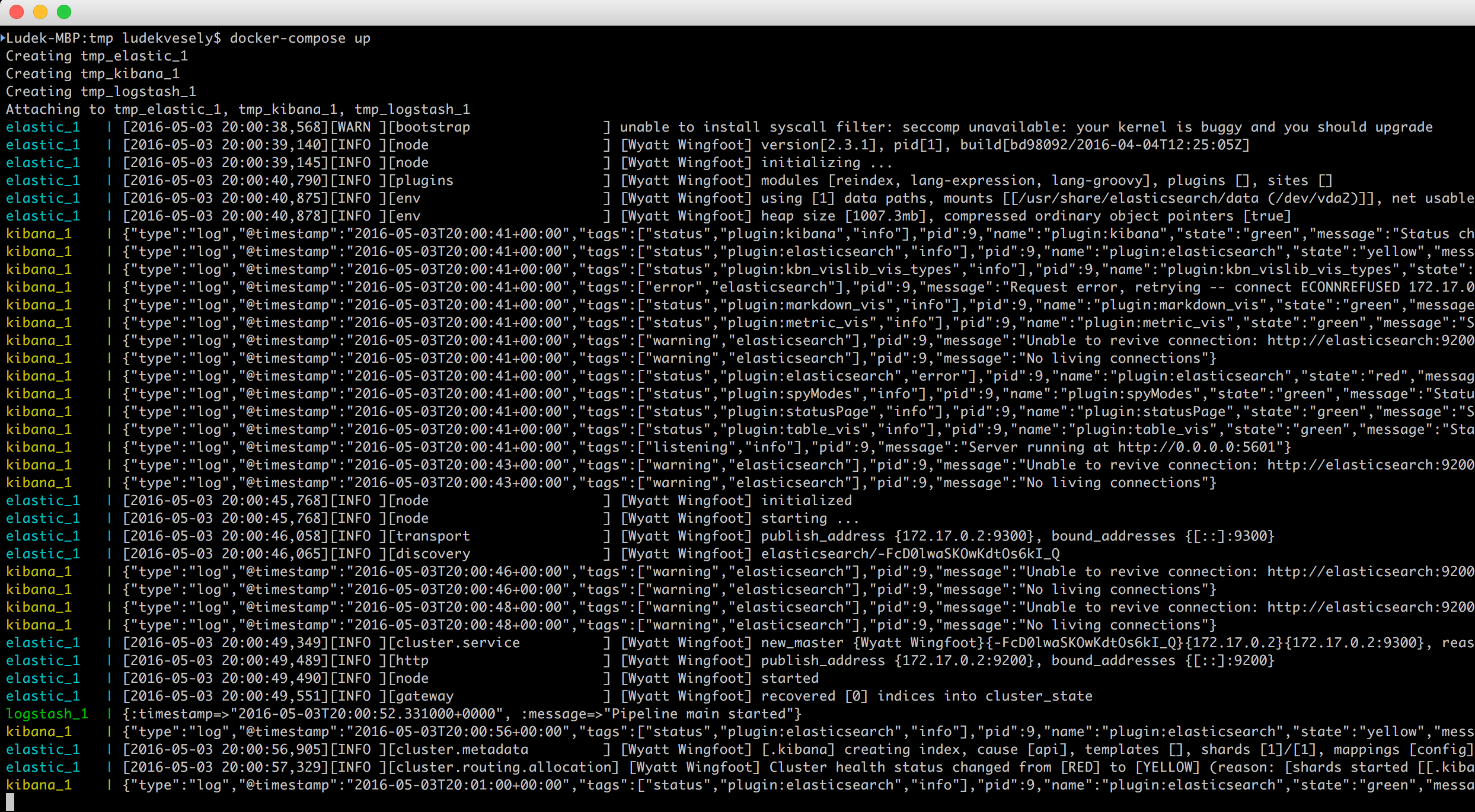
Nyní zapíšeme do Logstashe jednu zprávu. Otevřete další terminál a zadejte:
nc localhost 5000 <<< "This is my log message"
Zpráva This is my log message by měla být uložená v Elasticsearch. Nyní otevřete prohlížeč na adrese http://localhost:5601 a potvrďte výchozí nastavení. Dále přejděte do sekce Discover, měla by tam být vidět zalogovaná zpráva.
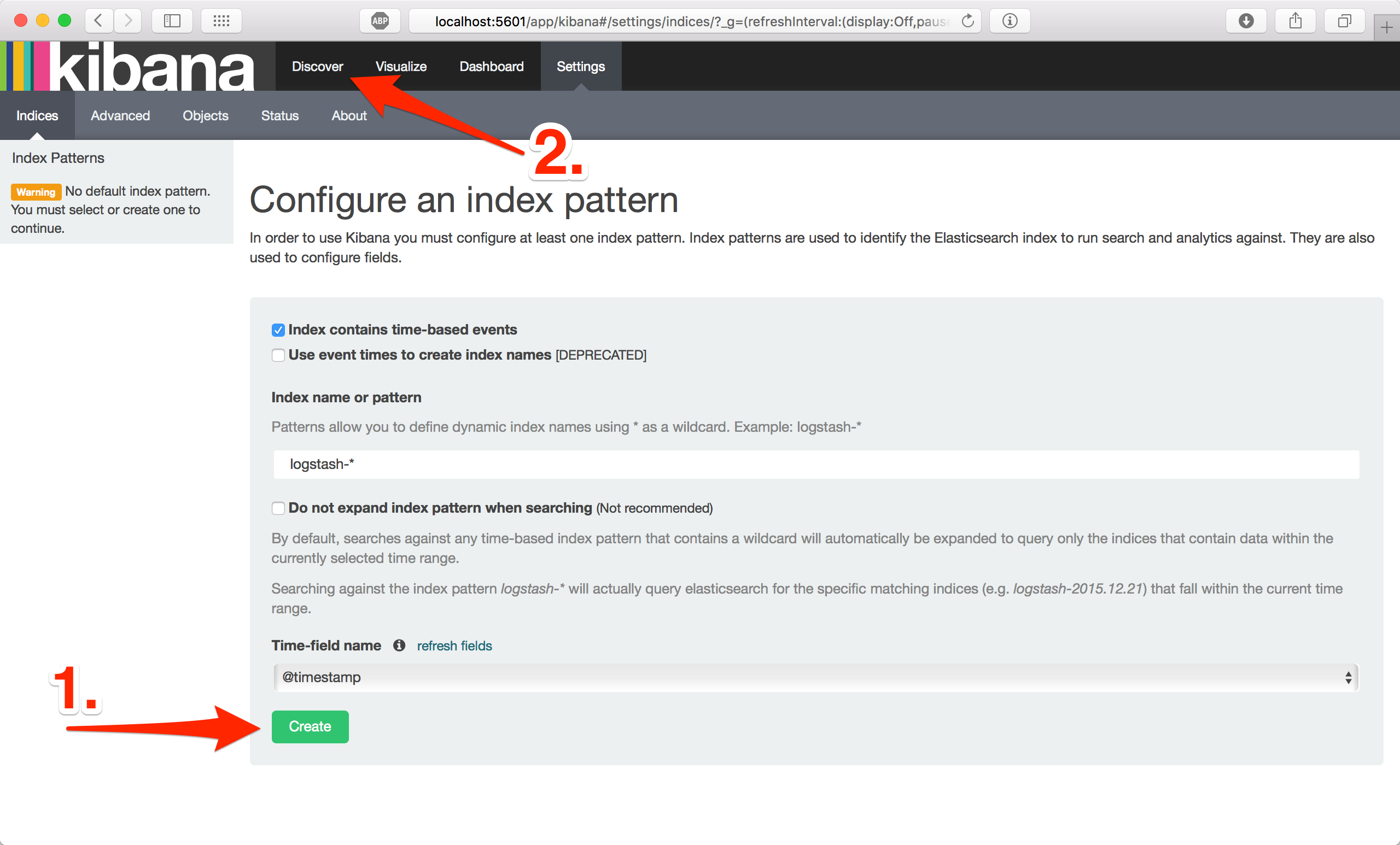
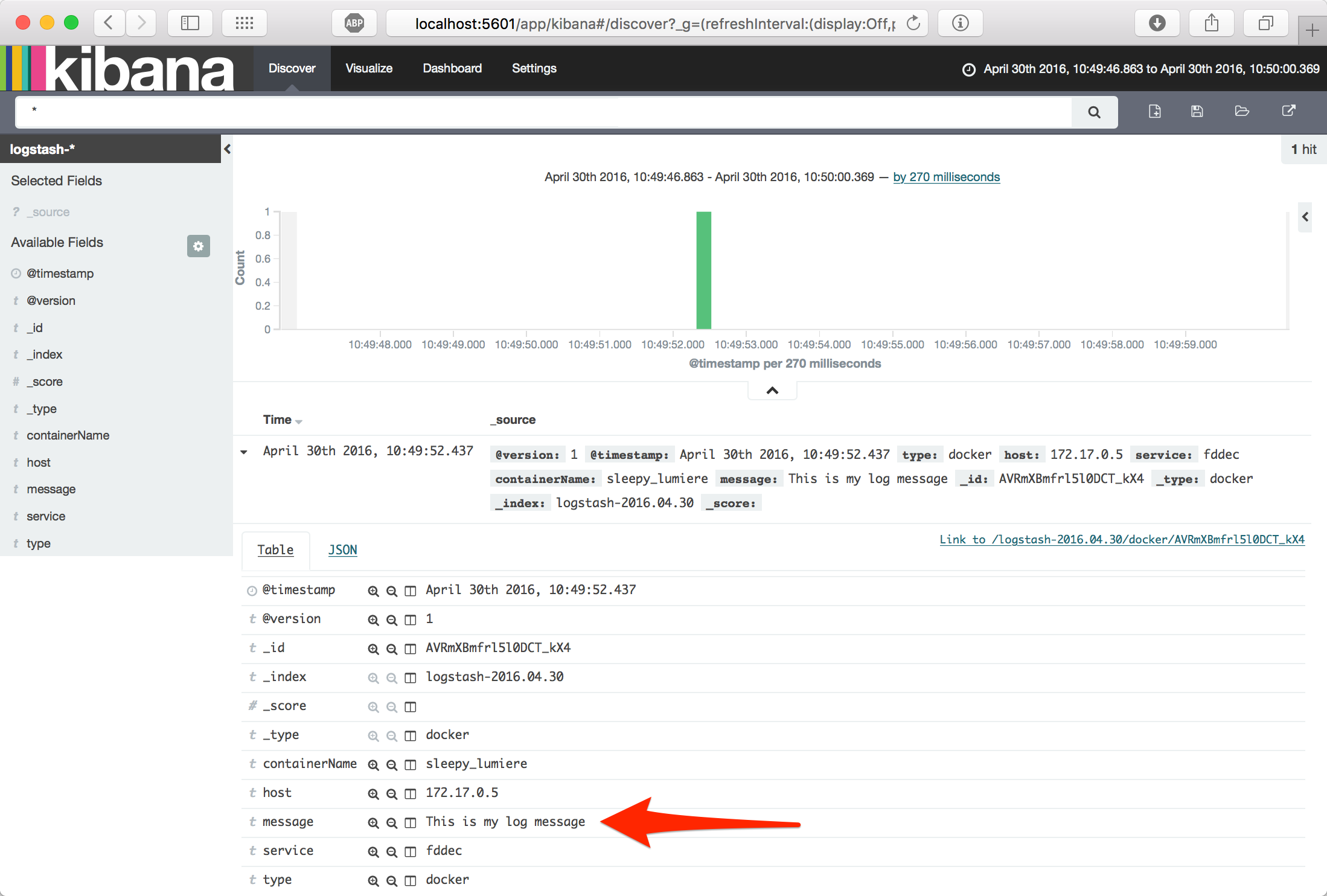
Pokud jste došli až sem, gratuluji, právě jste úspěšně spustili ELK Stack, zapsali zprávu do Logstashe, který ji uložil do Elasticsearche a následně zobrazili v Kibaně.
Propojení Dockeru a Elastic Stacku
Nyní stojíme před otázkou jak dostat logy kontejnerů do Logstashe. To je vzásadě možné několika způsoby:
1. Loguje samotná aplikace
Pokud máte v kontejneru vlastní aplikaci, můžete do ní doprogramovat zápis logů do Logstashe. Například v PHP pomocí Monologu - nastavíte adresu a port a vesele logujete. Zde je problém, jak získat ostatní logy, například webserveru nebo databáze. Lepší je dle mého všechny logy směřovat na standardní výstup a o sběr logů se postarat na úrovni Dockeru.
2. Aplikace loguje do souboru, Logstash jej čte jako vstup
Pokud už nyní logujete do souboru, nabízí se možnost jej zpřístupnit jako volume a Logstash nakonfigurovat, aby jej použil jsko vstup. Zde jsou problémy stejné jako výše, navíc je problém se sdílením souborů, pokud Docker běží na víc serverech.
3. Aplikace loguje na standardní výstup, logy sbírá další služba
Toto je lepší varianta - ke všem logům, které kontejnery produkují přistupuji jednotným způsobem. Ve výchozím stavu Docker zapisuje tyto logy jako JSON do filesystemu, zbývá tedy zajistit čtení těchto souborů.
4. Aplikace loguje na standardní výstup, kontejner má nastaveny logging-drivers
Obdoba předchozí varianty s tím rozdílem, že kontejneru při spuštění řeknete kam má logovat. Kontejner tak aktivně zapisuje logy na dané umístění, v předchozím případě je kontejner pasivní a logy jsou sbírány. Nahradíte tak výchozí logování do souboru ve formátu JSON. Tato funkčnost byla do Dockeru přidána ve verzi 1.6, aktuálně je k dispozici několik driverů, mezi issues na GitHubu jsem nalezl zmínku o driveru pro logstash, aktuálně je asi nejlepší variantou syslog.
Dále budu popisovat třetí variantu, protože umožní zapnutí logování nezávisle na běžících kontejnerech. Není teda nic měnit, jen se spustí další služba, která logy sbírá a přeposílá do Logstashe.
Sběr logů kontejnerů: logspout
Pro tento účel byl vytvořen nástroj logspout (GitHub, Docker Hub). Jde o připravený image, který se spustí, zpřístupní se mu socket docker démona skrz který čte logy všech běžících kontejnerů a přeposílá je dál. Automaticky zjišťuje nové kontejnery, takže existující stacky lze používat beze změny.
Propojení docker démona a logspoutu je pouze zpřístupněním souboru /var/run/docker.sock. Zbývá propojit logspout a Logstash. Logspout má několik adaptérů pro směřování výstupu: tcp, udp, syslog... Upravíme tedy soubor docker-compose.yml - doplníme sekci logspout:
logspout:
image: gliderlabs/logspout:v3
command: 'udp://logstash:5000'
links:
- logstash
volumes:
- '/var/run/docker.sock:/tmp/docker.sock'
kibana:
image: kibana
links:
- 'elastic:elasticsearch'
ports:
- '5601:5601'
logstash:
image: logstash
command: 'logstash -e "input { udp { port => 5000 } } output { elasticsearch { hosts => elastic } }"'
links:
- elastic
elastic:
image: elasticsearch
Dále jsem provedl změny v sekci logstash. Smazal jsem část s nastavením portů - k Logstashi přistupuje pouze logspout, což je automaticky zajištěno (kontenery v stacku na sebe vidí jako by byly na lokální síti), není tedy nutné ho zveřejňovat. Dále jsem upravil vstup Logstashe z tcp na udp. Nějakou dobu totiž trvá, než se Logstash spustí a pokud použiji spojení tcp, logspout ihned po spuštění skončí, protože se nemůže připojit na spouštějící se Logstash. UDP je nespojované spojení, logspout tak stále skouší zprávy poslat a je mu jedno, jestli na daném portu něco běží nebo ne, nevyžaduje žádné potvrzení.
Pokud vám ještě běžý starý stack, zabijte jej pomocí ctrl + c, případně i smažte kontejnery pomocí docker-compose rm -f. Nový stack spusťte opět příkazem docker-compose up.
Nyní jsou logy všech kontejnerů routovány přes logspout a Logstash do Elasticsearche. Můžeme zkusit spustit kontejner, který pouze zaloguje jednu zprávu a skončí:
docker run --rm alpine echo Hello world
Pokud se podíváte do Kibany na http://localhost:5601, na záložce Discover by měla být vidět jako poslední zalogovaná zpráva Hello world:
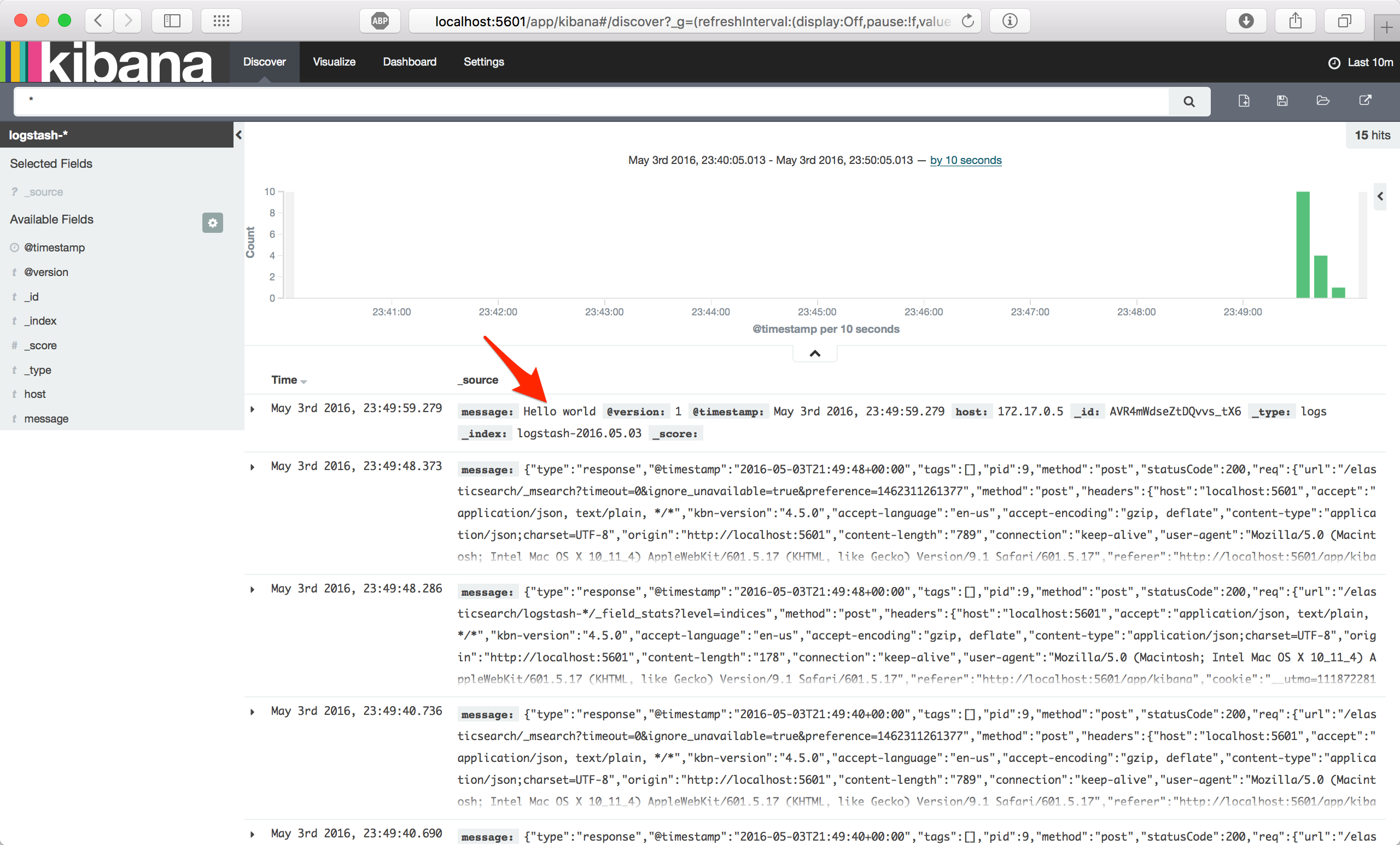
Jistě jste si všimli spousty zpráv zalogovaných níže. Logspout automaticky přijímá logy všech kontejnerů, tedy i běžící Kibany, Logstashe a Elasticsearche. Pokud nechcete logy některého kontejneru zpracovávat, je třeba mu přidat proměnnou prostředí LOGSPOUT shodnotou ignore. To je možné doplněním do souboru docker-compose.yml. Funkční konfigurace, kdy jsou agregovány logy všech kontejnerů kromě spuštěného Elastic Stacku by tedy vypadala následovně:
logspout:
image: gliderlabs/logspout:v3
command: 'udp://logstash:5000'
links:
- logstash
volumes:
- '/var/run/docker.sock:/tmp/docker.sock'
kibana:
image: kibana
links:
- 'elastic:elasticsearch'
ports:
- '5601:5601'
environment:
- LOGSPOUT=ignore
logstash:
image: logstash
command: 'logstash -e "input { udp { port => 5000 } } output { elasticsearch { hosts => elastic } }"'
links:
- elastic
environment:
- LOGSPOUT=ignore
elastic:
image: elasticsearch
environment:
- LOGSPOUT=ignore
Přidání názvu kontejneru do logů
Pokud použijeme spojení logspoutu a Logstashe přes UDP, nezjistíme z jakého kontejneru logy pochází. Abychom to zjistili, je nutné použít jako adaptér syslog. Pro to je třeba upravit nastavení logspoutu i Logstashe. V případě logspoutu stačí upravit v docker-compose.yml část command: 'udp://logstash:5000' na command: 'syslog://logstash:5000'. Obdobnou úpravu je třeba provést na vstupu Logstashe - namísto input { udp { port => 5000 } } použít input { syslog { port => 5000 } }. Do message uložené v Elasticsearch se tak dostane několik dalších informací, mimo jiné název kontejneru a název stacku. Taková zpráva vypadá následovně:
2016-05-03T22:32:26.510Z 172.17.0.5 <14>1 2016-05-03T22:32:26Z 79445d78c31a hopeful_goldstine 1936 - - Hello world
To však není úplně přehledné, je tedy ještě přidat sekci filter, která tuto zprávu zparsuje:
filter {
grok {
match => { "message" => "%{SYSLOG5424PRI}%{NONNEGINT:ver} +(?:%{TIMESTAMP_ISO8601:ts}|-) +(?:%{HOSTNAME:service}|-) +(?:%{NOTSPACE:containerName}|-) +(?:%{NOTSPACE:proc}|-) +(?:%{WORD:msgid}|-) +(?:%{SYSLOG5424SD:sd}|-|) +%{GREEDYDATA:msg}" }
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
mutate {
remove_field => [ "message", "priority", "ts", "severity", "facility", "facility_label", "severity_label", "syslog5424_pri", "proc", "syslog_severity_code", "syslog_facility_code", "syslog_facility", "syslog_severity", "syslog_hostname", "syslog_message", "syslog_timestamp", "ver" ]
}
mutate {
remove_tag => [ "_grokparsefailure_sysloginput" ]
}
mutate {
gsub => [
"service", "[0123456789-]", ""
]
}
if ("" in [msg]) {
mutate {
rename => { "msg" => "message" }
}
}
mutate {
remove_field => [ "tags" ]
}
}
Tím se ale stane zápis v docker-compose.yml dost nepřehledný, lepší je si vytvořit vlastní image - napsat Dockerfile. Jeden takový jsem vytvořil, je dostupný na Docker Hubu. Kromě zpracování zprávy ve formátu syslogu umí i zpracovat JSON, je tedy možné upravit vaši aplikaci tak, aby logovala ve formátu JSON a Logstash to automaticky zpracuje. Konečný docker-compose.yml bude vypadat následovně:
logspout:
image: gliderlabs/logspout:v3
command: 'syslog://logstash:5000'
links:
- logstash
volumes:
- '/var/run/docker.sock:/tmp/docker.sock'
logstash:
image: ludekvesely/logstash-json
environment:
- DROP_NON_JSON=false
- STDOUT=false
links:
- elasticsearch
kibana:
image: kibana
environment:
- LOGSPOUT=ignore
links:
- elasticsearch
ports:
- '5601:5601'
elasticsearch:
image: elasticsearch
environment:
- LOGSPOUT=ignore
Nyní bude v Kibaně k dispozipi zalogovaná zpráva včetně názvu kontejneru a stacku. V případě, že byla zpráva ve formátu JSON, bude i ten zpracován. Ted už zbývá vytvořit par přehledných tabulek a grafů v Kibaně a uložit si je jako dashboard.
Poslední úpravou před spuštěním na produkci bude pravděpodobně nastavení volume pro Elasticsearch, aby data přežila restart kontejneru. Nezapomeňte zabezpečit Kibanu, aby nebylo přístupná celému světu (například pluginem do ES Shield/SearchGuard). Pokud nechcete Kibanu kontrolovat každý den, nastavte si notifikace (plugin do ES Watcher nebo ElastAlert).
Zdroje:
- http://nathanleclaire.com/blog/2015/04/27/automating-docker-logging-elasticsearch-logstash-kibana-and-logspout/
- https://blog.tutum.co/2015/05/26/log-searching-and-analysis-with-tutum-and-an-elk-2/
- https://www.zdrojak.cz/clanky/sber-logu-z-kontejneru
- http://www.slideshare.net/raychaser/6-million-ways-to-log-in-docker-nyc-docker-meetup-12172014
- http://pt.slideshare.net/sematext/docker-logging-webinar
- https://www.loggly.com/blog/top-5-docker-logging-methods-to-fit-your-container-deployment-strategy/